






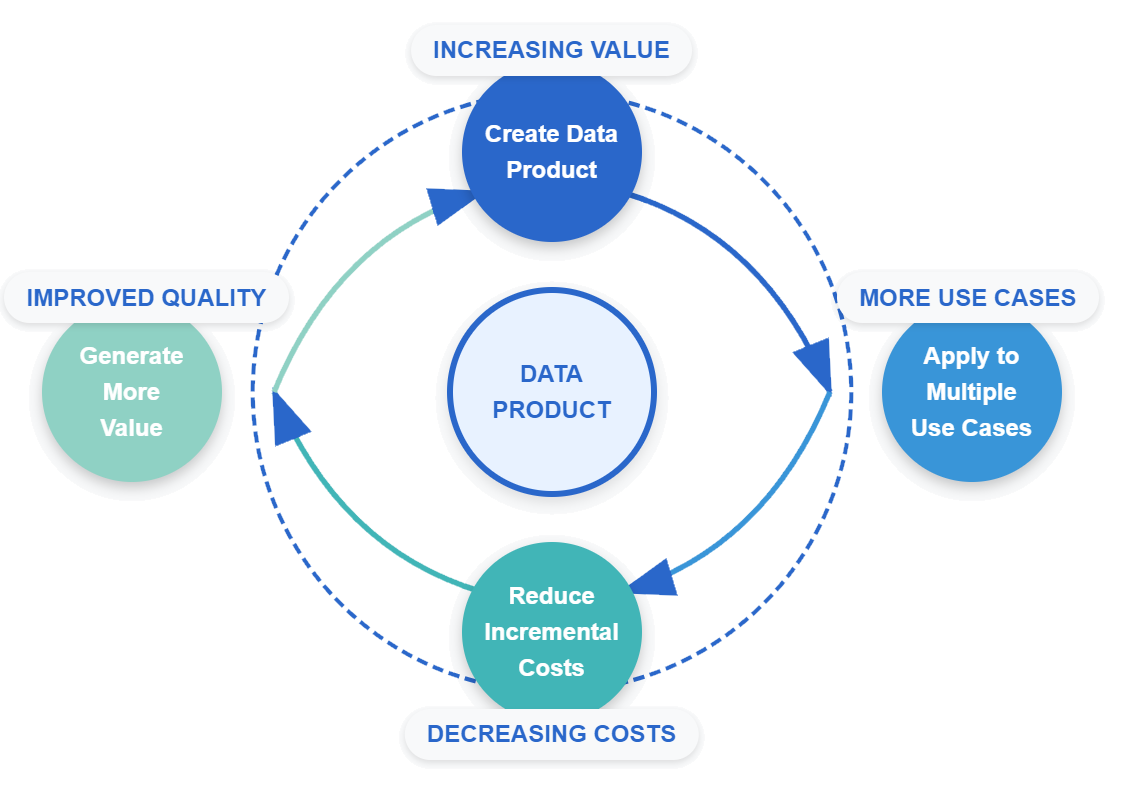
The Data Product Flywheel
Treating data as a product to increase value and decrease costs.

McKinsey’s recent article “The missing data link: Five practical lessons to scale your data products” has hit on something I’ve been advocating for years: treating data as a product rather than a project or resource. While I’m typically wary of consultancy research (aren’t we all?), this piece validates much of what we’ve observed in the field about the transformative power of data product thinking.
From Train Cars to Data Products
McKinsey’s transportation analogy resonated with me: “Imagine you were a railway executive with a contract to transport valuable cargo across the country. You wouldn’t have a different engine pulling each individual car of cargo.” Yet this is exactly how most organizations approach their data—as siloed initiatives each requiring their own infrastructure, management, and governance.
The result? Fragmentation, waste, inefficiency, and ultimately, untapped value. Sound familiar?
This aligns perfectly with my longstanding view that product thinking creates coherence and scalability. As I wrote in Technical Skills in Product Management, understanding a product’s technical domain enables product managers to “make informed decisions about the product roadmap and ensure that new features align with the product vision and strategy.” The same principle applies to data products.
The Data Product Flywheel Effect
What’s particularly powerful about McKinsey’s research is the quantification of what they call the “flywheel effect”—the compounding benefits of treating data as a product.
Have you seen how differently organizations perform when they grasp this concept versus when they treat each data initiative as its own island?
This cycle creates two powerful effects:
- Watching Costs Steadily Decrease: As data products are reused, one-time investments in quality, governance, and architecture get amortized across multiple use cases
- Accelerating Value Capture: Companies can deploy new use cases up to 90% faster, dramatically increasing time-to-value
Let me visualize this flywheel effect:
Five Key Principles for Data Product Success
Based on McKinsey’s research and my own experience in product management, here are five principles for successful data product implementation:
1. Focus on Value, Not Just Better Data
Too many organizations become enamored with data for data’s sake. The goal isn’t the data—it’s solving business problems. Start by mapping high-value use cases, then cluster those that rely on similar data. This gives you a clear roadmap of which data products to build first.
What’s the most valuable thing your organization could do with better data right now? That’s where your first data product should focus.
2. Understand Data Product Economics
Unlike traditional projects, data products deliver increasing returns over time. Their value increases as they enable more use cases while costs decrease with each reuse. This fundamentally changes how we should calculate ROI on data investments.
Under the hood, this is basically the opposite of how most IT projects work. Instead of diminishing returns over time, you get accelerating returns—if you structure things right.
3. Design for Evolution and Scalability
The “unsexy but critical blocking and tackling” of data engineering makes or breaks a data product program. Build data products with the flexibility to evolve as new requirements emerge, maintain simplicity, and create standardized connection technologies.
4. Find Data Product Leaders Who Think Like Business Leaders
The most successful data product programs are led by people who treat data products like a business, not just a technology initiative. They track KPIs, look for new use cases, and are accountable for generating value—not just building infrastructure.
In my experience, this is where most data initiatives fall short. They’re led by technical experts who understand data architecture but not the business context in which their data products will operate.
5. Integrate AI To Accelerate Development
Gen AI is already proving that it can help develop better data products faster (as much as three times faster) and cheaper than other methods, according to McKinsey’s research. From automating data relationships to generating transformation code, AI tools can dramatically increase the speed and quality of data products.
This aligns with broader research showing that generative AI is transforming product development across industries. McKinsey’s study on software product development found that “PMs who used gen AI tools…took less time, on average, to complete activities,” with productivity improvements of up to 40% when using AI to synthesize research and create documentation (McKinsey, 2024).
Companies like Eaton are already working to leverage these capabilities, with a vision to “take our traditional design processes from months to minutes” (aPriori, 2024).
The Missing Link in Many Organizations
What’s striking to me is how all of this aligns with what I’ve been coaching about product management for years. The skills that make great product managers—understanding user needs, balancing technical feasibility with business viability, and designing sustainable systems—are precisely the skills needed to create successful data products.
Yet many organizations continue to treat data as:
- A technical problem to be solved by IT
- A compliance necessity managed by risk teams
- A collection of siloed projects without a coherent strategy
This disconnected approach explains why, despite massive investments in data lakes, analytics, and dashboards, only a small fraction of organizations capture the full potential value from their data. It’s not that they don’t spend enough—it’s that they don’t think about data as a product that evolves and creates value over time.
Moving Forward
If your organization is struggling to generate value from data initiatives, consider whether you’re truly treating data as a product. Ask yourself:
- Do you have empowered data product owners accountable for generating value?
- Are you measuring the reuse of your data products across multiple use cases?
- Have you mapped high-value business cases to identify which data products to build?
- Is your data engineering designed for evolution and reuse?
The answers to these questions will likely reveal whether you’re positioned to create a data product flywheel—or if you’re still approaching data as disconnected train cars, each requiring its own engine.
What’s your experience with data products? Are you seeing the flywheel effect in your organization?