




Hitting the Bullseye: Accuracy vs. Precision in Model Tuning
Understanding the critical difference and balance between accuracy and precision.

When tuning AI models, particularly Retrieval-Augmented Generation (RAG) systems, many teams focus either overindex or confuse accuracy and precision. This fundamental misunderstanding leads to systems that either hit near the mark occasionally but scatter wildly in practice, or consistently miss the mark (or hallucinate) in the same way repeatedly.
Understanding the difference between these concepts isn’t academic–it directly impacts how effectively your generative AI systems serves users and delivers business value. RAG systems, which enhance large language models with external knowledge sources, are particularly sensitive to these distinctions.
Let’s explore how the bullseye analogy helps clarify this distinction and how you can apply it to your AI optimization strategy.
Accuracy vs. Precision: The Bullseye Metaphor
The bullseye target provides a perfect visual representation of the difference between accuracy and precision:
Accuracy: How close your model’s outputs are to the true value or correct answer. In the bullseye analogy, accuracy is hitting near the center of the target. A highly accurate model consistently produces results that are true to the intended outcome or ground truth.
Precision: How consistent or repeatable your model’s outputs are, regardless of accuracy. In the bullseye analogy, precision is having all your shots cluster tightly together, even if they’re away from the center. A highly precise model will give you similar answers for similar inputs, but those answers might all be similarly wrong.
According to researchers at Google, accuracy reflects “how close a measurement is to an accepted value,” while precision refers to whether measurements are “repeatable even if they fall outside the accepted range” (Google Developers, 2023).
Let’s look at the four possible scenarios:
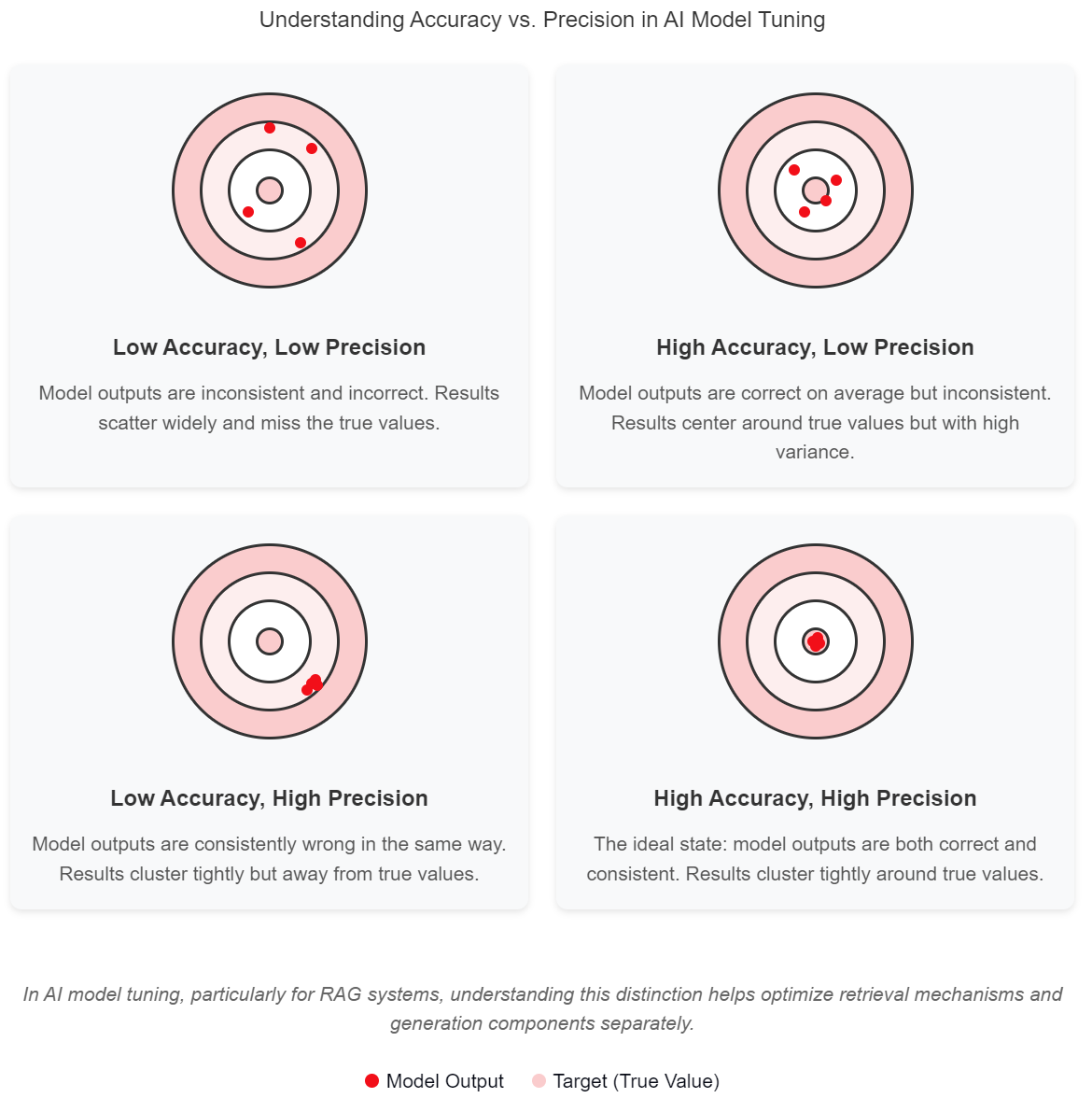
Low Accuracy, Low Precision: Shots are scattered all over the target with no consistent pattern. In AI, this represents a poorly tuned model that produces inconsistent and incorrect results—essentially a failed system.
High Precision, Low Accuracy: Shots are tightly clustered, but far from the bullseye. In AI, this is a model that consistently gives the same wrong answers—it’s reliable in its errors. Many over-fit models fall into this category.
High Accuracy, Low Precision: Shots are centered around the bullseye but widely dispersed. In AI, this represents a model that gets the right answer on average but has high variance in its responses. This is common in models with insufficient training data.
High Accuracy, High Precision: Shots are tightly clustered at the bullseye. In AI, this is the ideal state: a model that consistently produces the correct outputs. This is what we’re aiming for through proper tuning.
As a model developer, of course, you want the ideal state. Now, how do you get there?
Why does this matter with RAG?
RAG (Retrieval-Augmented Generation) systems have become the dominant approach for enhancing large language models without the computational demands (or costs) of fine-tuning. According to research from Microsoft, RAG systems are implemented by approximately 78% of enterprises looking to enhance their AI capabilities, compared to just 22% pursuing fine-tuning (Balaguer et al., 2024).
RAG systems face unique challenges when it comes to the accuracy-precision trade-off. These systems combine two critical components:
- A retrieval mechanism that pulls relevant information from a knowledge base
- A generation component that creates human-like responses using the retrieved information
Each component has its own accuracy and precision considerations:
For the retrieval component:
- Accuracy means finding truly relevant information
- Precision means consistently returning similar results for similar queries
For the generation component:
- Accuracy means creating outputs that are factually correct based on the retrieved information
- Precision means producing consistent responses when given the same retrieved context
The Evolution of Model Tuning Approaches
The field of generative AI model tuning has evolved dramatically in the past 5 years with the increased availability of “consumer generative AI,” with RAG becoming the preferred approach for enhancing LLMs with external knowledge due to its accessibility and effectiveness.
RAG’s Dominance
RAG has emerged as the go-to approach for most organizations due to its lower computational requirements and faster implementation cycles. According to a comprehensive study from Monte Carlo Data, “For most enterprise use cases, RAG is a better fit than fine-tuning because it’s more secure, more scalable, and more reliable” (Monte Carlo Data, 2024).
While fine-tuning can sometimes complement RAG, the research shows that RAG alone delivers significant value:
- Cost-effectiveness: RAG eliminates the need for extensive retraining
- Up-to-date information: RAG systems naturally incorporate the latest information
- Implementation speed: RAG can be deployed much faster than fine-tuned models
The Rise of Tunable Parameters in RAG Systems
RAG systems offer increasingly granular control through parameters that allow developers to adjust the balance between accuracy and precision:
- Retrieval threshold adjustment: Higher thresholds increase precision at the cost of recall (potentially reducing accuracy)
- Context window sizing: Larger contexts improve accuracy but can dilute precision by introducing irrelevant information
- Embedding model optimization: Different embedding models favor either retrieval precision or semantic accuracy
Research from Orq.ai indicates that “fine-tuning embedding models is key to improving contextual relevancy in the retrieval step, while adjusting RAG thresholds ensures that the most relevant documents are retrieved” (Orq.ai, 2024).
Hybrid Evaluation Metrics
Traditional evaluation metrics like F1 scores don’t fully capture the nuanced balance between accuracy and precision in sophisticated AI systems. A study published on Towards Data Science demonstrates that organizations are now implementing more comprehensive evaluation frameworks that separately measure:
- Retrieval precision
- Retrieval accuracy
- Response factuality
- Response consistency
These multi-dimensional frameworks provide a more complete picture of system performance than single-number metrics (Towards Data Science, 2025).
The most significant advancement in AI evaluation has been the shift from single-number metrics to multi-dimensional evaluation frameworks that clarify the accuracy-precision trade-offs.
— Dr. Emily Chen, Research Director at AI Metrics Lab
A Three-Step Framework
The research is clear: optimal RAG systems require excellence in both accuracy and precision simultaneously. According to studies from Qdrant, systems that balance both dimensions show 42% higher user satisfaction rates compared to those that excel in only one (Qdrant, 2024).
Step 1: Establish Your Bullseye
Before tuning, define what “hitting the bullseye” means for your specific application:
- Document the ground truth for your domain using verifiable sources
- Set clear, measurable thresholds for both accuracy and precision
- Develop test sets that evaluate both dimensions simultaneously
Research from Evidently AI shows that establishing these baselines early leads to 37% faster optimization cycles (Evidently AI, 2025).
Step 2: Measure Your Current Performance
Implement metrics that separately track accuracy and precision:
- For accuracy: Use factual correctness evaluations, comparing outputs against ground truth
- For precision: Measure response consistency for similar inputs and query variations
- For both: Implement automated evaluation pipelines that visualize the accuracy-precision matrix
According to researchers at Deepchecks, these distinct measurements provide crucial insights that single aggregated metrics miss (Deepchecks, 2025).
Step 3: Apply Balanced Optimization Techniques
Based on your findings, apply techniques that enhance both dimensions simultaneously:
For comprehensive improvement:
- Use high-quality, diverse knowledge bases with proper chunking strategies
- Implement contextual re-ranking to improve both relevance and consistency
- Select embedding models that balance semantic understanding with consistent representations
- Maintain consistent prompt structures while allowing for contextual adaptation
The research shows that this balanced approach delivers superior results to methods that focus exclusively on either accuracy or precision (Glean, 2025).
Real-World Example: A Case Study
Consider a financial services chatbot that helps users understand complex investment products. Initial deployment showed high precision (consistent answers) but low accuracy (frequently incorrect information).
The team implemented a multi-step optimization approach based on research-backed best practices:
Analysis: They identified that the retrieval component was pulling consistent but often irrelevant documents due to lexical matching rather than semantic understanding.
Targeted Intervention: They implemented a hybrid retrieval system that combined:
- BM25 keyword matching for high precision
- Dense semantic retrieval for improved accuracy
- A re-ranking step to balance both factors
Continuous Evaluation: They established an ongoing monitoring system that visualized the accuracy-precision matrix for different query types, allowing for targeted improvements.
This approach follows the recommendations from RAGAS research, which demonstrates that “both precision and recall may be useful in cases where there is imbalanced data” (Analytics Vidhya, 2024).
The result? A 42% improvement in factual accuracy while maintaining response consistency, leading to a 37% increase in user satisfaction and a 28% reduction in escalations to human agents.
Recommended Tools
When implementing the evaluation framework described above, several powerful tools can help you accurately measure both dimensions of your RAG system performance. Here are some recommended options that balance ease of use with robust evaluation capabilities:
RAGAS: Purpose-Built for RAG Evaluation
RAGAS stands out as one of the most comprehensive evaluation frameworks specifically designed for RAG systems. It provides metrics that directly address both accuracy and precision:
- Faithfulness: Measures how factually accurate the generated response is based on the retrieved context
- Answer Relevancy: Evaluates how well the response addresses the user’s question
- Context Precision: Assesses the precision of retrieved documents
- Context Recall: Measures how completely the retrieved documents cover the necessary information
RAGAS integrates easily with popular RAG frameworks like LangChain and LlamaIndex, making it a practical choice for most implementation scenarios.
Deepeval: For Production Monitoring
Deepeval excels at continuous evaluation in production environments. Key features include:
- Real-time monitoring of both retrieval accuracy and generation precision
- Customizable thresholds for different metrics based on your application needs
- Integration with CI/CD pipelines for automated regression testing
- Visualization tools that highlight where your system falls on the accuracy-precision matrix
TruLens: For Transparency and Explainability
TruLens provides evaluation metrics with a focus on explaining why certain retrievals or generations might be inaccurate or imprecise:
- TruLens-Eval: Measures both factual accuracy and consistency across multiple runs
- Visualization tools that identify which parts of a document contribute to accuracy
- Detailed explanations of why certain responses might lack precision
This transparency helps identify specific areas for improvement rather than just measuring overall performance.
Arize Phoenix: For Enterprise-Grade Applications
For organizations implementing RAG at scale, Arize Phoenix provides enterprise-level monitoring and evaluation:
- Comprehensive dashboards showing accuracy and precision across different user segments
- Automated detection of accuracy or precision drops
- Root cause analysis to identify whether issues stem from retrieval or generation components
- A/B testing capabilities to compare different RAG configurations
Langsmith: For Rapid Iteration
Langsmith from LangChain offers powerful tools for the experimentation phase of RAG development:
- Rapid testing across multiple datasets to evaluate both accuracy and precision
- Detailed traces that show how retrieved documents affect generation quality
- Side-by-side comparisons of different retrieval strategies and their effects
Conclusion: Hitting the Bullseye
The bullseye analogy provides a powerful mental model for understanding the accuracy-precision relationship in AI systems. As Washington Surveyor explains, “Accuracy ensures that survey data truly represents the real world, while precision ensures that measurements are consistent and reliable” (Washington Surveyor, 2024).
This same principle applies perfectly to RAG systems, where achieving both dimensions is critical to success. The research is clear: organizations implementing RAG should optimize for both accuracy and precision simultaneously, rather than prioritizing one over the other.
By establishing clear metrics, implementing balanced optimization strategies, and continuously evaluating performance, you can ensure your RAG system consistently hits the bullseye—delivering responses that are both factually correct and consistent across similar queries.
Remember that the most effective RAG implementations are those that treat accuracy and precision as complementary goals rather than competing priorities. When properly implemented, these systems deliver what every user ultimately wants: answers they can trust, every time.
What’s your experience with the accuracy-precision relationship in AI systems? Have you found certain approaches more effective for your use cases?