Modernizing C++ : Building Rock Solid Stability
The first pillar in transforming legacy code into modern, reliable systems.

We’ve all been there—inheriting a decade-old codebase, with tens of thousands of lines written by developers who have long since moved on. The code works (mostly), but making changes feels like defusing a bomb while blindfolded.
One of my hobbies involves working with an ever-mutating open source project dating back to the early 2000s. The code is fragile–an error usually results in a kernel exception and full crash. While we still inherit from the main branch, I spend a great deal of time reviewing, modernizing, and adding tests to every aspect of the code.
The key question: how do we modernize without breaking the functionality and introducing unknowns into the system?
I see modernization as a three-pillar approach. This series will explore each pillar in depth, starting with what I consider the foundation of any modernization effort: Stability.
THE STABILITY CHALLENGE
Stability isn’t just about preventing crashes. It’s about creating systems that behave predictably, handle errors gracefully, and don’t leak resources. Unfortunately, C++ makes it particularly easy to shoot yourself in the foot… with a bazooka.
A report from Microsoft’s security response center indicates that approximately 70% of the security vulnerabilities they address are memory safety issues—many of which could be prevented with modern C++ practices.
Common stability killers in legacy C++ code include:
- Raw pointer mismanagement leading to memory leaks, dangling pointers, and overflows
- Manual resource handling without proper cleanup
- Inconsistent error handling strategies
- Undefined behavior lurking in unexpected places
- Difficult-to-maintain interdependencies between components
Quick Aside: I also frequently hear how “obsolete” C++ is. It’s not. The most recent stable edition, C++23, was released in October 2024 (5 months ago at time of writing) and the language continues to grow. According to RedMonk, C++ and CSS (disgusting, CSS is not a language) are tied at #7 in most used languages based on their usage criteria (github repos, stack overflow Q&A, etc).
ADOPTING RAII AND SMART POINTERS
The Resource Acquisition Is Initialization (RAII) pattern is hardly new—it’s been a cornerstone of C++ for decades—but I’m constantly surprised by how many codebases underutilize it.
At its core, RAII ties resource management to object lifetime: resources (like memory, file handles, network connections, and locks) are acquired during object construction and released during object destruction. This seemingly simple pattern has profound implications for code reliability.
Why is this so powerful? Because C++ guarantees that destructors are called when objects go out of scope, even when exceptions occur. By linking resource cleanup to destructors, we ensure resources are released in all code paths—normal returns, early returns, and exceptions. This eliminates an entire category of bugs related to resource leaks.
Let’s look at a before-and-after example:
Old approach:
void processData(const std::string& filename) {
FILE* file = fopen(filename.c_str(), "r");
if (!file) {
// Error handling
return;
}
Data* data = new Data();
// Process file, potentially returning early on errors...
if (error_condition) {
fclose(file);
delete data;
return;
}
// More processing...
fclose(file);
delete data;
}
Modern approach:
void processData(const std::string& filename) {
std::ifstream file(filename);
if (!file) {
// Error handling
return;
}
auto data = std::make_unique<Data>();
// Process file, potentially returning early on errors...
if (error_condition) {
return; // Resources automatically cleaned up
}
// More processing...
// No need for manual cleanup
}
The modern version eliminates two categories of bugs (forgotten resource cleanup and exception-unsafe code) while actually becoming more concise.
Notice how the modern approach:
- Automatically handles file closure, even if errors occur
- Manages memory without explicit delete calls
- Removes the need to repeat cleanup code at every exit point
- Eliminates the possibility of resource leaks if we later add new exit paths
Smart pointers (std::unique_ptr, std::shared_ptr, and std::weak_ptr) should be your default choice for managing dynamically allocated objects. They communicate ownership semantics clearly and eliminate most memory leaks by design.
Beyond just preventing leaks, proper RAII adoption delivers several other benefits:
- Reduced cognitive load: Developers don’t need to track which resources need cleanup
- Self-documenting code: The code structure clearly shows resource lifetimes
- Exception safety: Resources are properly cleaned up even when exceptions occur
- Composability: RAII objects can be composed to manage multiple resources safely
In my experience, consistently applying RAII principles has been a huge unlock for me in how I approach my project’s stability efforts.
MODERN ERROR HANDLING
Error handling in C++ has evolved significantly. While exceptions remain the primary mechanism, newer C++ versions have added tools to make error handling more robust and expressive.
Traditional C++ error handling often relies on error codes, boolean return values, or out parameters—approaches that can be inconsistent, easy to ignore, and fail to communicate the nature of errors. Modern techniques offer better alternatives that provide clarity, type safety, and enforcement of error handling.
Let’s examine the evolution of a simple parsing function:
Old approach:
bool parseConfig(const std::string& input, Config* config) {
if (input.empty()) {
return false;
}
// Parsing logic...
return success;
}
// Usage
Config config;
if (!parseConfig(input, &config)) {
// Handle error, but what exactly went wrong?
}
Modern approach:
enum class ConfigError {
EmptyInput,
InvalidFormat,
MissingRequiredField
};
std::expected<Config, ConfigError> parseConfig(const std::string& input) {
if (input.empty()) {
return std::unexpected(ConfigError::EmptyInput);
}
// Parsing logic...
return Config{...};
}
// Usage
auto configResult = parseConfig(input);
if (!configResult) {
switch (configResult.error()) {
case ConfigError::EmptyInput:
// Handle specific error
break;
// Handle other cases...
}
}
Quick Aside: I’ve chosen the traditional function declaration style above, but have found myself migrating to the trailing return type syntax as I modernize:
auto parseConfig(const std::string& input) -> std::expected<Config, ConfigError> {
// Implementation identical to above
}
The trailing return type style (using auto and ->) offers several advantages:
- Consistency with lambdas, which use this syntax
- Easier reading of complex return types (particularly function pointers)
- Better support for decltype expressions in return types
- The function name appears earlier in the declaration, improving readability for complex functions
Whichever style you choose, consistency across your codebase is more important than the specific choice.
C++23’s std::expected gives us type-safe error handling without the overhead of exceptions. For C++17 projects, libraries like tl::expected provide similar functionality.
The modern approach offers several key advantages:
- Error type safety: Errors are represented as proper enumerated types rather than ambiguous integers or booleans
- Impossibility of ignoring errors: The calling code must handle the result or explicitly discard it
- Rich error information: Different error conditions are clearly distinguished
- Self-documenting interfaces: The function signature itself communicates error possibilities
- Composition: Error-returning functions can be easily chained together
Another option is std::optional (available since C++17), which works well when there’s only one possible error condition or when the exact error doesn’t matter:
std::optional<Config> parseConfig(const std::string& input) {
if (input.empty()) {
return std::nullopt;
}
// Parsing logic...
return Config{...};
}
When deciding between exceptions, expected, and optional, consider:
- Use exceptions for truly exceptional conditions that should terminate normal program flow
- Use expected for anticipated errors that have different types/causes and need specific handling
- Use optional for simpler functions where the only important information is success/failure
A cohesive error-handling strategy dramatically improves code stability by ensuring errors are properly detected and handled throughout the application.
In my experience, adopting consistent, modern error handling has taken our server uptime for this project to nearly 100%–even with the user base trying everything they can to break things.
But what about error handling across API boundaries? Consider adopting a strategy where:
- Internal components use a consistent error handling mechanism (like
std::expected) - Public APIs translate these errors into appropriate forms for external consumers Error categories are well-defined and documented
This layered approach maintains error fidelity without constraining how your code is used by others.
TESTING AND VERIFICATION
You can’t ensure stability without comprehensive testing. Modern C++ projects should leverage the rich ecosystem of testing and analysis tools available.
In legacy codebases, testing is often an afterthought—manual tests, sparse unit tests, or reliance on integration testing alone. This approach inevitably lets bugs slip through, especially when refactoring. A modern testing strategy involves multiple complementary layers:
Unit Testing Frameworks
- Catch2: My personal favorite for its simplicity and powerful features
- Google Test: Robust and widely used, especially in large projects
- Doctest: Lightweight and fast, great for header-only integration
Here’s a simple example using Catch2 to test our earlier configuration parser:
TEST_CASE("Config parser handles various inputs", "[config]") {
SECTION("Empty input returns appropriate error") {
auto result = parseConfig("");
REQUIRE(!result.has_value());
REQUIRE(result.error() == ConfigError::EmptyInput);
}
SECTION("Valid input returns proper configuration") {
auto result = parseConfig("valid_config_string");
REQUIRE(result.has_value());
// Check specific properties of the configuration
REQUIRE(result->someProperty == expectedValue);
}
SECTION("Malformed input returns format error") {
auto result = parseConfig("malformed_string");
REQUIRE(!result.has_value());
REQUIRE(result.error() == ConfigError::InvalidFormat);
}
}
This test provides a clear contract for how the function should behave, serving as both documentation and verification.
Many believe that unit testing in C++ is difficult, if not impossible, but there are plenty of great libraries to create tests as succintly as in Python, Typescript, or C#.
Static Analysis Tools
- Clang-Tidy: Checks for potential bugs, style violations, and modernization opportunities
- Cppcheck: Useful for detecting memory leaks and buffer overflows
- SonarQube: Commercial tool for comprehensive code quality analysis
Static analyzers act as an automated code review, catching issues before code even runs. For modernization projects, I configure them to flag outdated patterns like raw pointers, C-style casts, and error-prone constructs.
A typical .clang-tidy configuration might include:
Checks: 'modernize-*,cppcoreguidelines-*,performance-*,bugprone-*,-modernize-use-trailing-return-type'
WarningsAsErrors: true
CheckOptions:
- key: modernize-use-nullptr.NullMacros
value: 'NULL,nullptr'
This configuration enables checks that flag old-style code and recommendations from the C++ Core Guidelines.
I’m very slowly becoming more comfortable with having end-to-end builds in cmake vs. Visual Studio solutions. Kicking off clang-tidy and cppcheck as part of the compile process is as easy as:
set(CMAKE_CXX_LANG_TIDY "clang-tidy;-yourParamsHere")
Dynamic Analysis
- Valgrind: Detects memory management and threading bugs
- AddressSanitizer: Fast memory error detector
- UndefinedBehaviorSanitizer: Runtime undefined behavior detection
Dynamic analyzers find issues that only manifest at runtime. They’ve repeatedly saved me from subtle bugs that would have been catastrophic in production. Enabling sanitizers in CMake is straightforward:
set(CMAKE_CXX_FLAGS_DEBUG "${CMAKE_CXX_FLAGS_DEBUG} -fsanitize=address -fsanitize=undefined")
Testing Strategy for Modernization
When modernizing existing code, follow this testing sequence:
- Write characterization tests: Document current behavior exactly as it is, even bugs
- Add instrumentation: Run with sanitizers to find hidden issues
- Apply static analysis: Clean up issues that don’t change behavior
- Refactor incrementally: Maintain test coverage as you modernize
- Add property-based tests: Verify invariants that should hold for all inputs
For challenging legacy code, consider using the Approval Tests library, which excels at capturing and verifying complex existing behavior. Integrating these tools into your CI/CD pipeline ensures that stability issues are caught early. A mature pipeline might look like:
- Build with warnings as errors
- Run static analyzers
- Execute unit tests
- Run sanitizer-instrumented tests
- Perform integration tests
- Deploy to staging
- Run end-to-end tests
In my current project, this comprehensive approach caught over 400 potential issues beyond ’normal errors’; I now have a stability TODO list!
API DESIGN FOR STABILITY
One of the most impactful ways to improve stability is to design APIs that make it difficult to misuse them. This is where the concept of “making illegal states unrepresentable” comes in.
Modern C++ gives us powerful tools to design interfaces that catch errors at compile time rather than runtime. The type system becomes your first line of defense against bugs. As the saying goes: “Make the compiler your ally, not your enemy.”
Consider a function that processes a temperature reading:
Old approach:
void processTemperature(double temperature, int scale) {
// scale: 0 = Celsius, 1 = Fahrenheit, 2 = Kelvin
// ...
}
// Usage - oops, invalid scale
processTemperature(22.5, 3);
Modern approach:
enum class TemperatureScale { Celsius, Fahrenheit, Kelvin };
void processTemperature(double temperature, TemperatureScale scale) {
// ...
}
// Usage - compiler prevents invalid scale
processTemperature(22.5, TemperatureScale::Celsius);
The improved API uses strong typing to eliminate an entire class of errors at compile time. The enum class prevents implicit conversions and scopes the enumeration values, avoiding polluting the global namespace.
Let’s take this a step further with more advanced techniques:
// Even better approach - using strong types
template <typename Scale>
class Temperature {
private:
double value;
// Private constructor prevents direct creation
explicit Temperature(double val) : value(val) {}
public:
// Named factory methods for different scales
static Temperature<struct CelsiusTag> Celsius(double val) {
return Temperature<CelsiusTag>(val);
}
static Temperature<struct FahrenheitTag> Fahrenheit(double val) {
return Temperature<FahrenheitTag>(val);
}
static Temperature<struct KelvinTag> Kelvin(double val) {
return Temperature<KelvinTag>(val);
}
double getValue() const { return value; }
};
// Now our processing function can be type-safe
void processTemperature(Temperature<CelsiusTag> temp) {
// No need to specify scale - it's encoded in the type
double value = temp.getValue();
// ...
}
// Usage - even safer!
auto temp = Temperature::Celsius(22.5);
processTemperature(temp); // Works fine
auto tempF = Temperature::Fahrenheit(72.0);
// processTemperature(tempF); // Compilation error!
This approach makes it impossible to pass the wrong temperature scale - the compiler simply won’t allow it. You could even add conversion methods between the types for when that’s needed.
Other API design principles that enhance stability:
- Prefer immutable data structures where possible
- Make interfaces narrow and focused
- Use builder patterns for complex object construction
- Document preconditions and postconditions explicitly
- Return newly constructed objects instead of modifying through output parameters
GRADUAL ADOPTION STRATEGIES
One of the biggest challenges in modernizing a codebase is managing the transition. Rewriting everything at once is rarely feasible or wise.
I’ve seen many modernization efforts fail because they attempted to change too much too quickly. The most successful transitions maintain system stability throughout the process, delivering incremental value while gradually improving the codebase.
Here’s the approach that’s worked for me:
- Establish boundaries: Create clear interfaces between components that you’ll modernize first and the rest of the codebase
- Prioritize high-risk areas: Start with code that has a history of bugs or handles critical functionality
- Write tests before changing code: Ensure existing behavior is preserved
- Create parallel implementations: Build modern versions alongside legacy code and gradually shift traffic
- Use feature flags: Toggle between old and new implementations to manage risk
Let’s look at each of these strategies in more detail:
Establishing Boundaries
Start by identifying natural boundaries in your system where you can create clean interfaces. These interfaces act as abstraction layers between modernized and legacy code.
// Before: Direct usage of legacy code throughout the codebase
void someFunction() {
LegacyClass* obj = new LegacyClass();
obj->legacyMethod();
// More direct usage...
delete obj;
}
// After: Interface-based approach
class DataProcessor {
public:
virtual ~DataProcessor() = default;
virtual Result process(const Data& data) = 0;
// Factory method
static std::unique_ptr<DataProcessor> create(bool useModernImplementation = false);
};
// Usage
void someFunction() {
auto processor = DataProcessor::create(featureFlags.useModernProcessor());
Result result = processor->process(data);
// No need to manage memory or know implementation details
}
The factory method can return either the modern or legacy implementation based on configuration, allowing for selective rollout.
Prioritizing High-Risk Areas
Not all code is equally critical. I recommend creating a heat map of your codebase based on:
- Frequency of past bugs and issues
- Critical functionality
- Performance bottlenecks
- Areas with highest technical debt
This approach ensures you get the most value from your early modernization efforts.
Tests as Safety Nets
Before changing any code, ensure you have tests covering the existing behavior. For legacy code without tests, consider using:
- Approval testing to capture current outputs
- Integration tests if unit testing is challenging
- Property-based tests to verify invariants
// Approval-style test for existing behavior
TEST_CASE("Legacy behavior is preserved", "[legacy]") {
// Set up test inputs matching production scenarios
auto input = createTestInput();
// Capture current behavior before modernization
auto legacyResult = legacyFunction(input);
// Switch to new implementation
auto modernResult = modernFunction(input);
// Verify results match exactly
REQUIRE(modernResult == legacyResult);
}
Parallel Implementations
When modernizing critical components, implement the new version alongside the old one:
class ModernImplementation : public DataProcessor {
public:
Result process(const Data& data) override {
// New implementation using modern C++ techniques
}
};
class LegacyImplementation : public DataProcessor {
public:
Result process(const Data& data) override {
// Wrapper around the legacy code
LegacyClass* obj = new LegacyClass();
auto result = obj->legacyMethod(data.toLegacyFormat());
delete obj;
return Result::fromLegacyResult(result);
}
};
std::unique_ptr<DataProcessor> DataProcessor::create(bool useModern) {
if (useModern) {
return std::make_unique<ModernImplementation>();
}
return std::make_unique<LegacyImplementation>();
}
This approach lets you compare results (specifically, in your unit tests) between implementations and gradually transition functionality.
Feature Flags for Risk Management
Feature flags provide fine-grained control over which code paths are active. Here’s an example of building pulling from a configuration file (I use lua for most of mine) and setting a default value if nothing is set in the configuration file (error proofing).
// Simple feature flag implementation
class FeatureFlags {
std::unordered_map<std::string, bool> flags;
public:
FeatureFlags() {
// Load from configuration file or environment
flags["use_modern_processor"] = getConfigValue("USE_MODERN_PROCESSOR", false);
// More flags...
}
bool useModernProcessor() const {
return flags.at("use_modern_processor");
}
// More getters...
};
// Global instance
const FeatureFlags featureFlags;
You can then gradually roll out features to production:
- Initially enable only in development environments or dependencies
- Then for a small percentage of production traffic
- Finally, for all production traffic
The following visualization shows one approach to incremental modernization:
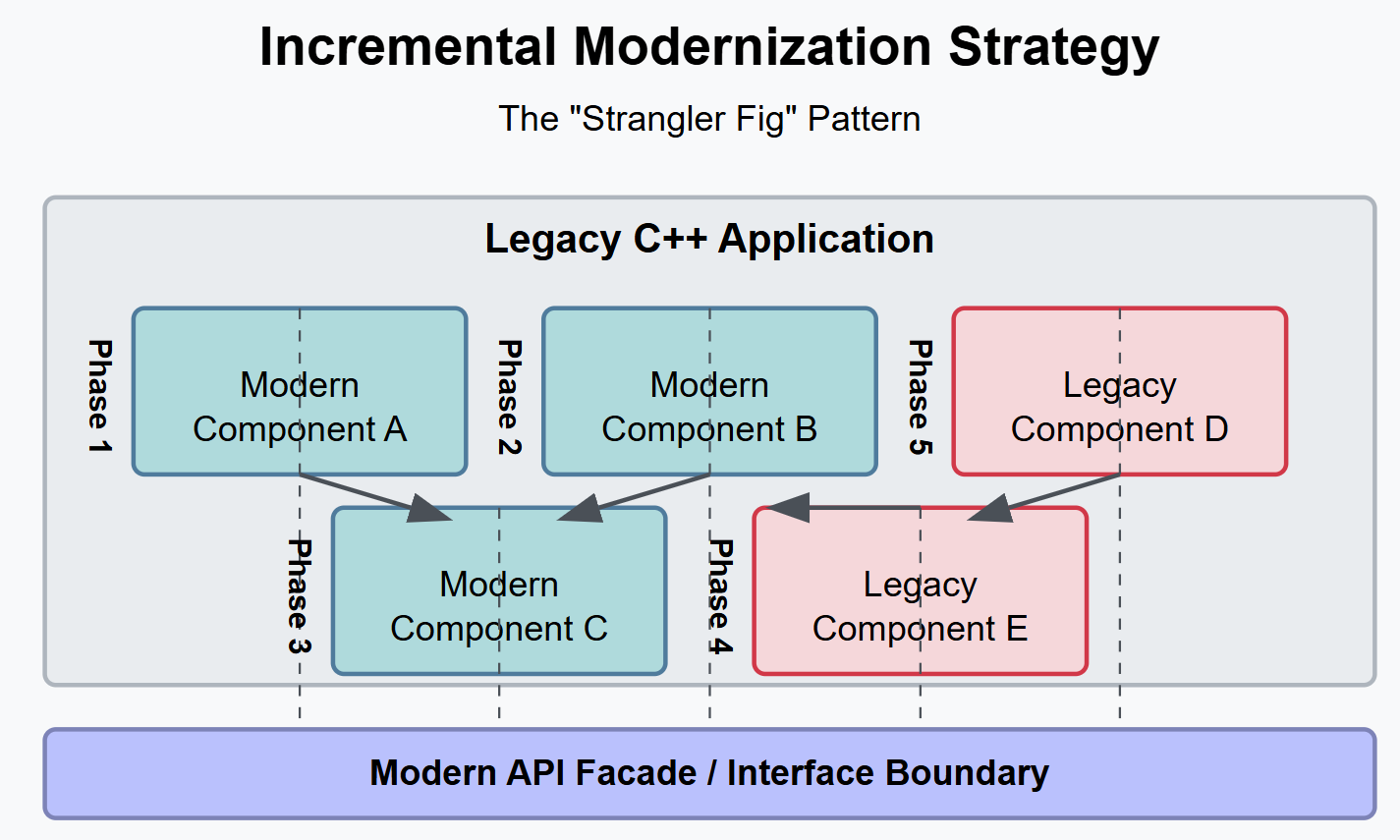
The “strangler fig” pattern (I don’t name these things) demonstrates how you create a facade and gradually replace legacy code while maintaining a working system throughout the process.
MEASURING STABILITY IMPROVEMENTS
How do you know if your modernization efforts are actually improving stability? Establish metrics before you begin:
- Crash rates and error frequencies from production
- Memory usage patterns
- Static analysis warning counts
- Test coverage percentages
- Time spent on bug fixes vs. new features
Without concrete measurements, it’s easy to feel like you’re making progress when you’re actually just moving code around without actually improving outcomes. The key is to focus on metrics that directly impact your goal, business value, or in the case of my project, santiy value.
Setting Up Effective Measurements
I recommend establishing a baseline measurement of stability metrics before starting any modernization work. This provides a clear before-and-after comparison that can demonstrate the value of your efforts to stakeholders.
Crash and Error Monitoring
Tools like Sentry, Bugsnag, or Crashpad can be integrated into your application to track crashes and exceptions in production. Look for:
- Overall crash frequency
- Crashes by component/module
- Most frequent error types
- Error occurrence patterns (time of day, load conditions, etc.)
A simple integration of Crashpad might look like:
// Initialize crash reporting
#include "crashpad/client/client.h"
#include "crashpad/client/settings.h"
void initializeCrashReporting() {
base::FilePath handler_path("path/to/crashpad_handler");
base::FilePath reports_dir("path/to/crashes");
base::FilePath metrics_dir("path/to/metrics");
std::string url("https://your-crashpad-server.example.com");
std::map<std::string, std::string> annotations;
std::vector<std::string> arguments;
crashpad::CrashpadClient client;
bool success = client.StartHandler(
handler_path, reports_dir, metrics_dir,
url, annotations, arguments,
true, true
);
if (success) {
crashpad::Settings* settings = client.GetSettings();
if (settings) {
settings->SetUploadsEnabled(true);
}
}
}
Memory and Resource Usage
Tools for monitoring memory usage include:
- Valgrind’s Massif for heap profiling
- Custom instrumentation using memory_resource
- Platform-specific tools like Windows Performance Monitor or Linux’s perf
Track metrics such as:
- Peak memory usage
- Memory usage patterns over time
- Resource leaks
- Allocation/deallocation rates
Static Analysis Metrics
Track the progress of static analysis warnings using Clang-Tidy (you can also run these as part of your build or CI process and export them to dashboards).
# Run clang-tidy and count warnings
warnings_before=$(clang-tidy --checks=modernize-* src/*.cpp 2>&1 | grep warning | wc -l)
# After modernization
warnings_after=$(clang-tidy --checks=modernize-* src/*.cpp 2>&1 | grep warning | wc -l)
echo "Reduced warnings by $((warnings_before - warnings_after))"
Test Coverage
Consider using tools gcov with lcov or OpenCppCoverage to track test coverage:
# Generate coverage data
g++ -fprofile-arcs -ftest-coverage -O0 -g src/*.cpp -o myapp
./run_tests.sh
gcov src/*.cpp
# Generate report
lcov --capture --directory . --output-file coverage.info
genhtml coverage.info --output-directory coverage_report
Visualizing Progress
Create a modernization dashboard that tracks these metrics over time. Here’s an example using a simple table format, though several build tools on github and other SCMs provide integrations for analytics output on build.
| Metric | Baseline | Current | Target | Progress |
|---|---|---|---|---|
| Crash rate (per 1K users) | 2.4 | 0.8 | 0.5 | 67% |
| Memory leaks | 12 | 3 | 0 | 75% |
| Static analyzer warnings | 843 | 217 | <100 | 84% |
| Test coverage | 43% | 78% | 85% | 83% |
| Bug fix time allocation | 65% | 30% | 20% | 78% |
This table provides at-a-glance visibility into your modernization progress and helps maintain momentum by showing concrete improvements.
In my experience, demonstrating these improvements has been crucial for maintaining support for modernization efforts. When you can see clear progress in stability metrics that impact your project (or business), it’s much easier to justified the ongoing effort.
Track these metrics over time to ensure your modernization efforts are paying off.
CONCLUSION: THE FOUNDATION FOR FURTHER IMPROVEMENTS
Stability is just the first pillar of my modernization strategy, but it’s the most critical. Without a stable foundation, attempts to improve performance or readability will likely introduce new problems.
Throughout this article, we’ve explored several key techniques for improving stability in C++ codebases:
- RAII and smart pointers eliminate resource leaks and make exception safety automatic
- Modern error handling with
std::expectedandstd::optionalmakes errors impossible to ignore - Comprehensive testing catches issues before they reach production
- Well-designed APIs prevent misuse at compile time
- Gradual adoption strategies ensure continuity during modernization
- Concrete measurements verify that improvements are making a real difference
These approaches have helped my team transform legacy codebases that were fragile and error-prone into robust, reliable systems that we can confidently extend with new features.
The journey to modernization isn’t just about adopting the latest language features—it’s about systematically addressing the root causes of instability and building a foundation for sustainable development. By focusing first on stability, you create the conditions necessary for future improvements in performance and readability.
In the next article in this series, we’ll explore the Performance pillar—how to make your modernized C++ code not just more stable, but also faster and more resource-efficient. We’ll dive into profiling techniques, algorithm selection, memory layout optimization, and how to leverage modern C++ features for better performance without sacrificing stability.
Remember that modernization is a journey, not a destination. Even the most modern C++ codebase today will need updating as the language and best practices continue to evolve. The key is to establish processes and patterns that make continuous modernization part of your development culture.







Share this post
Twitter
Facebook
Reddit
LinkedIn
Pinterest
Email